In this post I attempt to explore some basic intuition about the inverse function as a method to generate random variables.
PDF and CDF
Suppose there is a probability density function 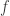

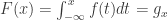
Where ![g_x \in [0, 1]](https://s0.wp.com/latex.php?latex=g_x%26nbsp%3B%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=303030&s=0&c=20201002)
PDF – example
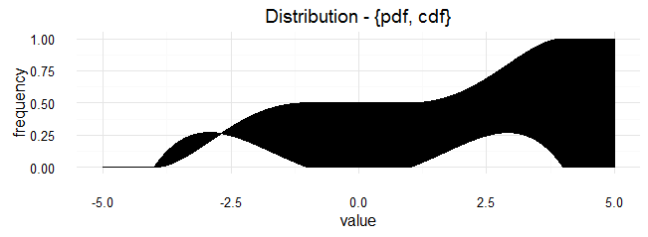
Let’s generate a probability density function 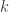


![{[-4, -1] \cup [+1, +4]}](https://s0.wp.com/latex.php?latex=%7B%5B-4%2C+-1%5D%26nbsp%3B%5Ccup%26nbsp%3B%5B%2B1%2C+%2B4%5D%7D&bg=ffffff&fg=303030&s=0&c=20201002)

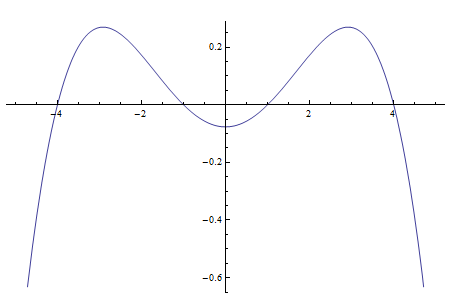
It is necessary to adjust this polynomial function to a factor of 
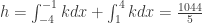
Therefore, the probability density function


By doing so, we can be confident that:

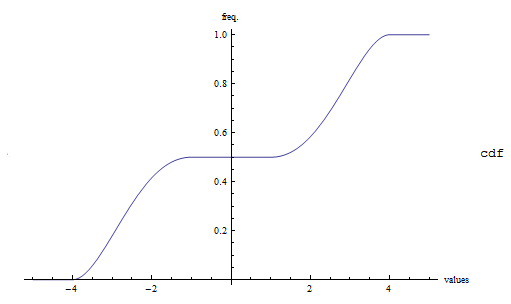
CDF – example
Naturally, the cdf function is just an integral. But due to the fact that the pdf we are using is a pisewise function, we must divide the integrals across the region. So the cdf function

We can figure the value of 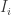





As a result we have:
Inverse function
The inverse function of 
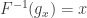
In more general terms, if 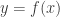
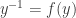

Example I
To begin with a simple example assume we have a pdf 


The cdf is then:

where:
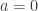



The inverse function 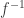
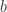

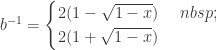
Since we expect that 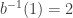
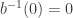

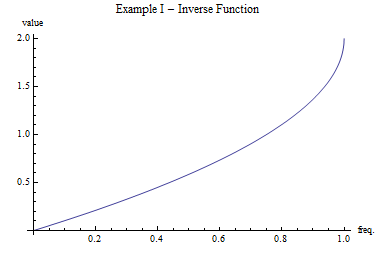
Example II
If we try to follow the same steps shown in Example I to calculate the inverse function of
At a first glance, switching from an analytical approach to a numeric method does not seem appealing. Nonetheless, in many cases we are better off working on a problem with a non-parametrical estimated density function (obtained from the empirical data) that with an analytical function determined by assumptions.
The first step is to have available the numeric data of the x-axis, pdf and cdf values.
| # Example of inverse function | |
| # Generating x-axis, pdf and cdf numeric values. | |
| # last modifyed: 29/04/2016 | |
| library(ggplot2) | |
| library(tibble) | |
| library(tidyr) | |
| # Mathematical function --------------------------------------------------- | |
| pdf_example <- function(x){ | |
| flag <- F | |
| if(x >= -4 & x <= -1) flag <- T | |
| if(x >= 1 & x <= 4) flag <- T | |
| if(flag) | |
| -5 * (x^2 - 1) * (x^2 - 16) / 1044 | |
| else | |
| 0 | |
| } | |
| # Create x-axis, pdf and cdf values -------------------------------------- | |
| n <- 5000 | |
| dataset <- data_frame( x = seq(-5, 5, 10/n )) | |
| dataset$pdf <- sapply(X = unlist(dataset$x), FUN = pdf_example) | |
| aux <- 0 | |
| freq_acum <- numeric() | |
| for(i in 1:(n+1)){ | |
| freq_acum[i] <- dataset$pdf[i] + aux | |
| aux <- dataset$pdf[i] + aux | |
| } | |
| dataset$cdf <- freq_acum / sum(dataset$pdf) | |
| dataset <- gather(dataset, dens, freq, -x) | |
| # Plot the results -------------------------------------------------------- | |
| g <- ggplot(dataset, aes(x, freq, group = dens)) + theme_minimal() + | |
| geom_ribbon(aes(ymin = 0, ymax = freq, fill = dens), alpha =0.6, color = "black") + | |
| xlab("value") + ylab("frequency") + scale_fill_brewer() + | |
| ggtitle("Dataset generated - {x-axis, pdf, cdf}") | |
| # g + geom_segment(aes(x = 0, xend = 0, y = 0, yend = 1/2), color = "dark blue", size = 0.75) + | |
| # geom_segment(aes(x = -5, xend = 0, y = 1/2, yend = 1/2), color = "dark blue", size = 0.75) | |

The cdf function
So let’s suppose that we want to know the value of 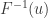

To maintain simplicity, linear interpolation is frequently used. Assume that the closest value to 

![\hat{x} = \frac{x[i+1]-x[i]}{z[i+1]- z[i]} (u - z[i]) + x[i]](https://s0.wp.com/latex.php?latex=%5Chat%7Bx%7D%26nbsp%3B%3D+%5Cfrac%7Bx%5Bi%2B1%5D-x%5Bi%5D%7D%7Bz%5Bi%2B1%5D-+z%5Bi%5D%7D+%28u+-+z%5Bi%5D%29+%2B+x%5Bi%5D&bg=ffffff&fg=303030&s=0&c=20201002)
Since we know that ![z[i] < u](https://s0.wp.com/latex.php?latex=z%5Bi%5D+%3C+u&bg=ffffff&fg=303030&s=0&c=20201002)
![z[i]](https://s0.wp.com/latex.php?latex=z%5Bi%5D+&bg=ffffff&fg=303030&s=0&c=20201002)
![u < z[i+1]](https://s0.wp.com/latex.php?latex=u+%3C%26nbsp%3Bz%5Bi%2B1%5D+&bg=ffffff&fg=303030&s=0&c=20201002)
![F^{-1}(z[i]) < F^{-1}(u) < F^{-1}(z[i+1])](https://s0.wp.com/latex.php?latex=F%5E%7B-1%7D%28z%5Bi%5D%29+%3C+F%5E%7B-1%7D%28u%29+%3C+F%5E%7B-1%7D%28z%5Bi%2B1%5D%29+&bg=ffffff&fg=303030&s=0&c=20201002)


Inverse method
If there is a random variable ![U[0,1]](https://s0.wp.com/latex.php?latex=U%5B0%2C1%5D&bg=ffffff&fg=303030&s=0&c=20201002)

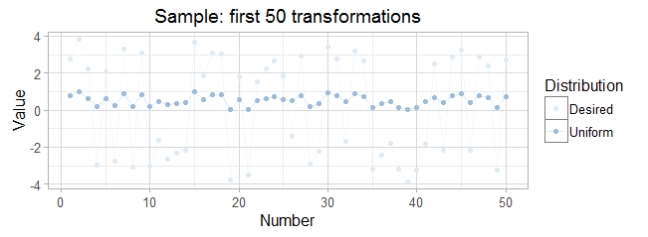
Then by using random uniformly distributed variables we can simulate any distribution. The following code shows the implementation of the numeric method to calculate the inverse function.
As a result, the inverse method allowed us to generate 5000 random variables that apparently distribute according to 

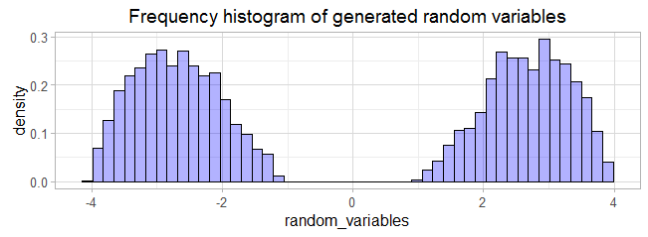
As it can be seen, the inverse method approach to generate random variables is a handy tool. The methodology allows us to apply this technique with analytical or numeric methods.
In further posts, we will explore how a density distribution can be estimated via non-parametric statistics. We will enhance monte-carlo simulations by doing so and hopefully build accurate predictive models. The inverse methodology is at the core of many high level simulations.